![Never lose track of your state]() AMPS makes a great platform for distributing messages to worker processes. The combination of low latency delivery, the SOW last value cache, message replay, and powerful content filtering make it easy to build a scalable grid of workers.
AMPS makes a great platform for distributing messages to worker processes. The combination of low latency delivery, the SOW last value cache, message replay, and powerful content filtering make it easy to build a scalable grid of workers.
In this post, we show how to extend the AMPS client to provide a bookmark store for workers that don’t maintain persistent state locally. The post assumes a good working knowledge of resumable subscriptions (covered in detail in the AMPS User Guide and the AMPS Java Developer Guide), and also assumes some familiarity with the implementations of the AMPS clients.
Complete source code for this post, including an AMPS configuration file and a class that loads sample data into AMPS, is available for download.
Keeping State in AMPS
To keep state in AMPS, we use the following three steps:
- Load state from AMPS when the application starts
- Periodically persist state to AMPS as the application performs work
- Flush the saved state to AMPS when the application shuts down
One way to use this technique is to maintain the point at which a particular worker should resume a subscription. To do this, we implement a BookmarkStore that uses AMPS for persistence.
There are lots of other ways to use this technique, of course. Yuck! Stateless Poison Message Handling shows a way to use the same technique to track messages that can’t be processed by a worker.
You can use varations on this technique to save the current state of a calculation or any other state that you need to track.
About Stores
The AMPS client libraries use stores to provide reliable publication and resumable subscriptions. Stores, as the name suggests, are used by the client to maintain state. The stores preserve the current state of the client. Bookmark stores save the state of incoming subscriptions. Publish stores save outgoing messages. For each type of store, the client library provides a simple interface, allowing you to choose the specific store implementation you want to use, or to write your own.
Bookmark Stores
Bookmark stores provide the following major functions:
- Add a bookmark to a subscription, indicating that a message has been received
- Remove a bookmark from a subscription, indicating that the message has been processed
- Return the most recent bookmark for a subscription, which is the point at which the subscription should resume
With bookmark live subscriptions, bookmark stores have one additional responsibility:
- Track which received messages have been persisted, and use those to help calculate the most recent bookmark
The AMPS clients include two varieties of bookmark stores. Memory-backed bookmark stores allow clients to resume after losing a connection to the server. In this case, the client loses state if the application that uses the client restarts. File-backed bookmark stores allow clients to resume after restarting. Some applications, though, need to be able to resume subscriptions without maintaining local state. For example, a set of worker tasks running on a virtual machine that is periodically re-provisioned can’t rely on persistent files to maintain state. Your application may want to present a consistent view of information whether the user is connecting from a desktop, a mobile phone, or through a website, without presenting messages that the user has already acted on.
The AMPS SOW is one way to preserve state for a client without relying on having access to a filesystem, or being able to access any resources other than AMPS itself. In this blog post, we’ll show you how to use AMPS as a bookmark store.
There are a few constraints to consider for creating the bookmark store. The solution needs to minimize the number of messages and the overall amount of data published to AMPS. While publishing to AMPS is fast, each message sent to AMPS consumes bandwidth between AMPS and the client. That bandwidth is often the most constrained resource for the application, so we need to use as little as possible. Last, but not least, it’s important to keep the solution simple, and use what’s already provided in the client wherever possible.
In addition, when a subscription uses the live option, the subscription receives messages that have not yet been persisted to the transaction log. This means that, if the server fails over, it is possible that the client has received messages that are not stored in the transaction log. In this case, AMPS periodically sends persisted acknowledgements on the subscription, which indicates the most recent point at which messages in the topic have been persisted. The bookmark store implementations provided with the AMPS clients track these acknowledgements, and the most recent method for those stores returns the latest persisted message rather than the latest discarded message. Using this strategy, the bookmark store guarantees that the client can restart from a valid message and will not miss messages even when using the live option.
To meet these constraints, the AMPS bookmark store takes this approach:
- Progress for the clients is stored in a SOW topic. This SOW topic need not be on the same server that publishes the messages. The SOW topic can be replicated, as well, to provide highly-available storage.
- Rather than persisting the entire state of the store to AMPS, keep the store in local memory and persist only the bookmark value for MOST_RECENT. When persisting the value, indicate whether the subscription is receiving persisted acknowledgements or not.
- Persist the most recent value to AMPS periodically, based on the number of messages processed for the subscription. This interval is configurable.
- Derive from MemoryBookmarkStore to take advantage of the logic that’s already written for duplicate handling, finding the correct value of MOST_RECENT, and maintaining quick in-memory access.
The rest of this post describes the implementation in detail.
Configuring The SOW
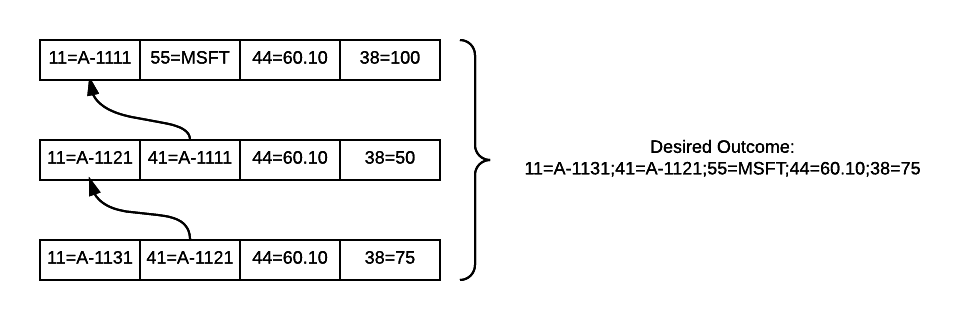
The records that hold the progress will contain the clientName, the subscription ID for every subscription tracked by that client, the last bookmark the client has persisted, and whether the subscriber is receiving persisted acknowledgements. Represented as JSON, each message will look something like this:
{"clientName":"resumableClient","subId":"sample-replay-id","bookmark":"10620414156524534001|3836|","persisted":"false"}
Messages in the SOW are uniquely identified using the clientName and subId fields. Because each client can have multiple subscriptions, each processing different bookmarks, the SOW definition creates a compound key where each unique combination of clientName and subId is a unique message. We define the SOW topic as follows:
<SOW><TopicDefinition><FileName>./sow/%n.sow</FileName><Topic>/ADMIN/bookmark_store</Topic><MessageType>json</MessageType><Key>/clientName</Key><Key>/subId</Key></TopicDefinition></SOW>
For this example, we use the JSON message type to make it easy to read the messages. This means that the instance that hosts the bookmark store needs to accept connections from clients that use the JSON message type.
We use the /ADMIN/ prefix as a way of indicating that this topic is used for application record keeping, and is not a topic that contains data. This is a convention to help with logging and troubleshooting, and is also intended to make it unlikely than any existing applications that use regex topic subscriptions will accidentally subscribe to this topic. However, the prefix has no meaning for AMPS itself, and the implementation could choose a different name.
Working with the BookmarkStore Interface
To get the results we need, there are three sets of methods we need to worry about on the BookmarkStore interface:
log() registers a message with the bookmark store to register the subscription and bookmark on the message. We don’t need to override this, since we’re planning to use the functionality that’s already provided, but we’ll call the log() function when we load the current state of the bookmarks from the SOW.discard() marks a message as processed, and allows the bookmark store to discard the message. Our new AMPS-based bookmark store will override this method. We’ll call the discard() method for the MemoryBookmark store and add code for persisting bookmarks to AMPS periodically.persisted() is called when the client receives a persisted acknowledgement. This marks a message as persisted, and allows the bookmark store to discard the message. For our implementation, we track that the subscription is receiving persisted acknowledgements and then call the MemoryBookmarkStore implementation.
For all of the other functionality of the bookmark store, the MemoryBookmarkStore does exactly what we need.
Defining the BookmarkStore Class
Next, it’s time to define the class for the bookmark store and a constructor. The constructor for the class takes the client to use to manage the bookmark store – which must already be connected – and the name of the client to track subscriptions for. Notice that the client used to track subscriptions doesn’t need to be connected to the same AMPS instance as the subscriptions being tracked.
publicAMPSBookmarkStore(ClientbookmarkClient,StringtrackedClientName)throwsAMPSException{if(bookmarkClient==null){thrownewAMPSException("Null client passed to bookmark store.");}_internalClient=bookmarkClient;_trackedName=trackedClientName;_bookmarkPattern=Pattern.compile("\"bookmark\" *: *\"([^\"]*)\"");_subIdPattern=Pattern.compile("\"subId\" *: *\"([^\"]+)\"");_persistedAckPattern=Pattern.compile("\"persisted\" *: *\"([^\"]+)\"");MessageStreamms=null;try{// Message to use for logging bookmarksMessagelogmsg=_internalClient.allocateMessage();// Retrieve state for this client.ms=_internalClient.sow("/ADMIN/bookmark_store","/clientName = '"+_trackedName+"'");for(Messagemsg:ms){if(msg.getCommand()!=Message.Command.SOW){continue;}Stringdata=msg.getData();MatcherbookmarkMatch=_bookmarkPattern.matcher(data);if(!bookmarkMatch.find())continue;MatchersubIdMatch=_subIdPattern.matcher(data);if(!subIdMatch.find())continue;MatcherpersistedAckMatch=_persistedAckPattern.matcher(data);if(!persistedAckMatch.find())continue;// Get the bookmark string, the subId, and whether this subscription// receives persisted acks.Stringbookmark=bookmarkMatch.group(1);StringsubId=subIdMatch.group(1);StringpersistedAcks=persistedAckMatch.group(1);// Extract individual bookmarks from the record if necessaryString[]bookmarks=newString[1];if(bookmark.contains(",")){bookmarks=bookmark.split(",");}else{bookmarks[0]=bookmark;}for(Stringb:bookmarks){// Create a message with the subId and bookmark// to use for logging with the MemoryBookmarkStore.logmsg.reset();logmsg.setSubId(subId);logmsg.setBookmark(bookmark);// Register the bookmark from the SOW as the// last successfully processed bookmark for this subId.super.log(logmsg);super.discard(logmsg);if(persistedAcks=="true"){super.persisted(logmsg.getSubIdRaw(),logmsg.getBookmarkRaw());_persistedAcks.add(logmsg.getSubId());}}_discardCounter.put(logmsg.getSubIdRaw(),0);}}catch(AMPSExceptione){System.err.println(e.getLocalizedMessage());e.printStackTrace(System.err);throwe;}finally{if(ms!=null)ms.close();}// Start the worker to asynchronously handle updates_workerThread=newThread(newUpdatePublisher(_internalClient,_trackedName,_workQueue),"Bookmark Update for "+_trackedName);_workerThread.start();}
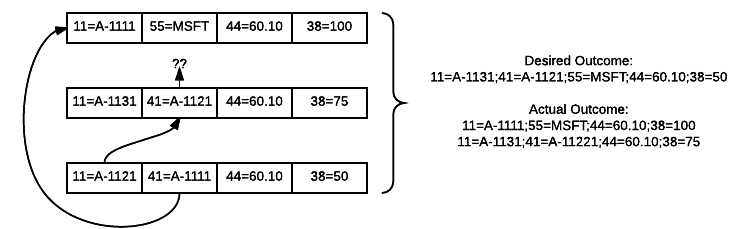
The constructor stores the client and the name of the client to track. The constructor then runs a SOW query on the topic that stores the persisted bookmarks and processes the results.
The persisted message for the subscription contains either a single bookmark, or a comma-delimited set of bookmarks. If the message contains a list, the constructor processes the bookmarks one at a time.
For each persisted bookmark, the constructor creates a message that contains the subscription ID and bookmark. The constructor logs the message, then immediately discards it. If the subscription has been receiving persisted acknowledgements, the constructor also logs an acknowledgement for the bookmark. This has the result of ensuring that the underlying MemoryBookmarkStore records the bookmark from the SOW query as the most recent bookmark for that subscription. The relevant lines are duplicated below:
// last successfully processed bookmark for this subId.super.log(logmsg);super.discard(logmsg);if(persistedAcks=="true"){super.persisted(logmsg.getSubIdRaw(),logmsg.getBookmarkRaw());_persistedAcks.add(logmsg.getSubId());}
To keep the sample self-contained, this class uses the standard Java regular expressions utility to process messages. In production, we would replace the regular expressions with one of the commonly-used JSON-parsing classes for Java.
Publishing Updates to the Store
While publish operations are very efficient with AMPS, the class takes the standard approach of trying to do minimal work within a message handler. In this case, because the discard() methods may be called within a message handler, the AMPSBookmarkStore uses a simple BlockingQueue to deliver the subscription IDs and bookmarks to a worker thread. The worker thread dequeues each request, creates a message, and publishes the message to the SOW.
Managing Discarded Messages
Next, we override the discard() method of the MemoryBookmarkStore. In the overrides, we check to see if it’s necessary to persist the bookmark to the SOW topic, and then call discard() on the MemoryBookmarkStore.
@Overridepublicvoiddiscard(Messagem)throwsAMPSException{super.discard(m);checkForPersist(m.getSubIdRaw());}
The checkForPersist() method checks the number of messages discarded for the subId. If the number of messages is higher than the configured threshold, the method writes the most recent bookmark to SOW storage.
privatevoidcheckForPersist(FieldsubId)throwsAMPSException{Integercount=_discardCounter.get(subId);if(count==null){count=0;}++count;if(count>_threshold){try{_workQueue.put(newUpdateRecord(subId.copy(),getMostRecent(subId)));count=0;}catch(InterruptedExceptione){thrownewAMPSException(e);}}_discardCounter.put(subId,count);}
The method checks the current count. If the count is above the configured threshold, the method enqueues an update and resets the counter. Otherwise, the method just increments the counter and returns. Notice that when the method enqueues an update, the method requests that the MemoryBookmarkStore provide the MostRecent value for the update. This ensures that the update contains the current recovery point.
The overrides for the persisted methods are equally simple:
@Overridepublicvoidpersisted(FieldsubId,BookmarkFieldbookmark)throwsAMPSException{super.persisted(subId,bookmark);_persistedAcks.add(subId.toString());}
In this case, we simply note that the subscription is getting persisted acknowledgements, and then call the MemoryBookmarkStore. Adding the subId to the set of persisted acks means that messages that note the most recent bookmark for this subscription will include the information that it gets persisted acknowledgements.
The worker that processes the update simply blocks until an update is submitted to the queue, then creates and publishes an update message.
while(true){UpdateRecordupdate=_workQueue.take();Stringmsg="{\"clientName\":\""+_trackedName+"\""+",\"subId\":\""+update.subId+"\""+",\"bookmark\":\""+update.bookmark+"\""+",\"persisted\":"+"\""+_persistedAcks.contains(update.subId.toString())+"\""+"}";_internalClient.publish("/ADMIN/bookmark_store",msg);}
Finally, we implement two utility methods. The close() method iterates all of the subscriptions tracked by the store, and calls updateSubscription for each subscription to store the state of the subscripton to the SOW.
publicvoidclose(){for(FieldsubId:_discardCounter.keySet()){try{_workQueue.put(newUpdateRecord(subId.copy(),getMostRecent(subId)));}catch(AMPSExceptione){e.printStackTrace();// Swallow exception: could also translate to unchecked// or log in the object.}catch(InterruptedExceptione){// Unable to update publish store. Recover at last saved bookmark// instead.e.printStackTrace();break;}}// Wait for the worker thread to drain the queue.while(!(_workQueue.size()==0&&_workerThread.getState()==Thread.State.WAITING)){Thread.yield();}_workerThread.interrupt();try{_workerThread.join();}catch(InterruptedExceptione){e.printStackTrace();// trying to close, continue}_internalClient.close();_internalClient=null;}
The setPersistEvery() method sets the number of messages to process for a subscription between snapshots of the bookmark into the SOW.
publicvoidsetPersistEvery(intmessageCount){_threshold=messageCount;}
The rest of the bookmark store interface, and the internal logic for managing the in-memory store is provided by the existing MemoryBookMarkStore.
Using the Store
Using the store from an HAClient is simple. You construct the store with the client to use for persistence and the name of the client to track. For example, the code snippet below creates an AMPSBookmarkStore that uses an existing client:
// control_client is connected to the AMPS instance that hosts the bookmark storeHAClientclient=newHAClient("Query-Client");DefaultServerChoosersc=newDefaultServerChooser();sc.add("tcp://amps-server:9007/amps");// Server to subscribe toclient.setServerChooser(sc);AMPSBookmarkStorestore=newAMPSBookmarkStore(control_client,client.getName());store.setPersistEvery(10);client.setBookmarkStore(store);client.connectAndLogon();
Once the bookmark store is set, you use the client just as you would with any other bookmark store. For example, using the Command interface introduced with the 4.0 clients:
BookmarkMessageHandlerhandler=newBookmarkMessageHandler(client);client.executeAsync(newCommand("subscribe").setTopic("messages-history").setSubId(newCommandId("sample-replay-id")).setBookmark(Client.Bookmarks.MOST_RECENT),handler);
Notice that, just as with any other resumable subscription, we set the subscription ID and we ask to start the subscription from the MOST_RECENT bookmark in the bookmark store. The provided sample also uses a bookmark message handler that exits after processing ten messages: this allows you to see how the bookmark store works for resuming after the last processed message.
Next Steps: High Availability Bookmark Stores
Because the topic that stores the bookmarks is just a normal SOW topic in AMPS, you can add high availability to the bookmark store without changing the AMPSBookmarkStore class itself.
To do this, you’d make the following changes:
- Add a transaction log for the
/ADMIN/bookmark_store topic. - Replicate the topic to another AMPS instance.
- Provide an HAClient as the control client for the
AMPSBookmarkStore, with the two AMPS instances in the server chooser for the client.
Wrapping it Up
While this post has been a deep dive into using AMPS itself as a BookmarkStore, the techniques in the post apply to any sort of state your application may need.
Just to review, the overall technique is:
- Restore state from the SOW when the application starts
- Periodically save state to the SOW as the application runs
- Flush the saved state when the application exits
Have a different pattern for maintaining application state in AMPS? Let us know in the comments!
 One of the best things about AMPS is the way that it keeps publishers completely independent from subscribers. Publishers don’t need to know how many subscribers are listening for a message, where they are, or even whether they’re connected at a given point in time. That flexibility pays off: once publishers are set up, you can use the same message stream for any number of different applications, without changing the publisher.
One of the best things about AMPS is the way that it keeps publishers completely independent from subscribers. Publishers don’t need to know how many subscribers are listening for a message, where they are, or even whether they’re connected at a given point in time. That flexibility pays off: once publishers are set up, you can use the same message stream for any number of different applications, without changing the publisher. AMPS is built from the ground up to go fast. AMPS tries to deliver messages at the fastest rate that an individual consumer can handle. AMPS has sophisticated machinery to try to find the fastest possible delivery rate for an individual consumer, and AMPS works hard
AMPS is built from the ground up to go fast. AMPS tries to deliver messages at the fastest rate that an individual consumer can handle. AMPS has sophisticated machinery to try to find the fastest possible delivery rate for an individual consumer, and AMPS works hard AMPS makes a great platform for distributing messages to worker processes. The combination of low latency delivery, the SOW last value cache, message replay, and powerful content filtering make it easy to build a scalable grid of workers.
AMPS makes a great platform for distributing messages to worker processes. The combination of low latency delivery, the SOW last value cache, message replay, and powerful content filtering make it easy to build a scalable grid of workers. CIO Review recently published “Scale Up and Out: The Changing Face of High Performance Computing” by Jeffrey M. Birnbaum. This article describes the state of high performance computing, and how things have changed since 1998.
CIO Review recently published “Scale Up and Out: The Changing Face of High Performance Computing” by Jeffrey M. Birnbaum. This article describes the state of high performance computing, and how things have changed since 1998.

 At 60East, we’ve been heads down in the lab, mixing up new ingredients to bring you the future of messaging today. We’ve just released AMPS 4.3.1.0.
At 60East, we’ve been heads down in the lab, mixing up new ingredients to bring you the future of messaging today. We’ve just released AMPS 4.3.1.0.
 Why is it that the latest Bugatti Veyron
Why is it that the latest Bugatti Veyron  When your needs change, hardware appliances can make you feel like you’re spinning your wheels.
When your needs change, hardware appliances can make you feel like you’re spinning your wheels. I’ve been pondering for a while on how to showcase some replay functionality in our AMPS product in a way that’s general enough that everyone understands the concept, yet provides a solution metaphor that easily translates into other domains. Ideally, the data would be from some real-world system, where time-series, ordering, and content filtering could be useful (again, leveraging the features of the product I’m trying to explain.)
I’ve been pondering for a while on how to showcase some replay functionality in our AMPS product in a way that’s general enough that everyone understands the concept, yet provides a solution metaphor that easily translates into other domains. Ideally, the data would be from some real-world system, where time-series, ordering, and content filtering could be useful (again, leveraging the features of the product I’m trying to explain.)

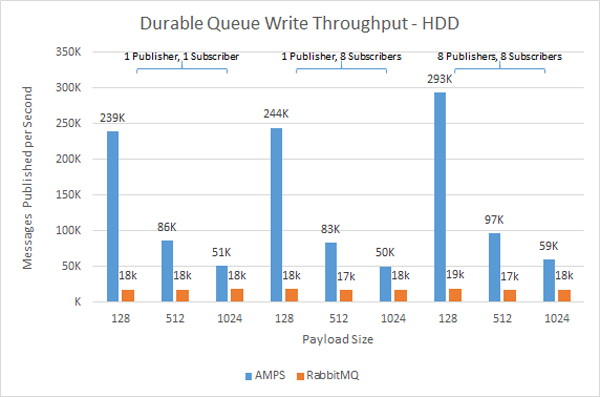
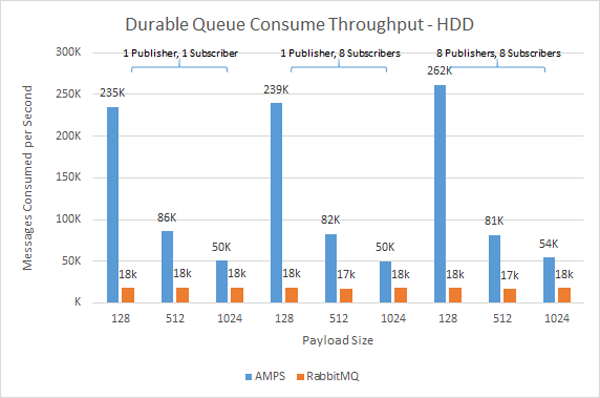
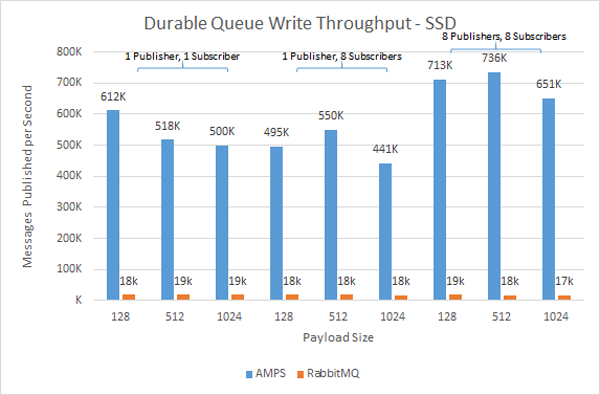
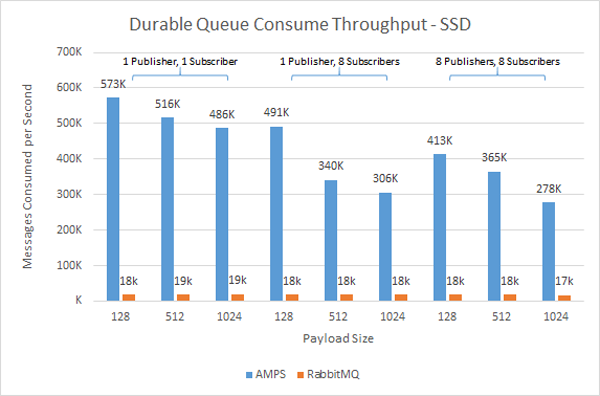


 Here at 60East, we’re dedicated to messaging.
Here at 60East, we’re dedicated to messaging. In this post, we will revisit the topic of extending the AMPS client to provide a bookmark store for stateless clients. This post is in response to requests for a simple stateless store that does not provide all of the functionality of the local stores, but instead just makes it possible for an application with very simple needs to pick up a subscription after failover. The implementation that we will discuss here is fairly limited, but should provide a starting point for less restrictive implementations. Before we begin, I would like to encourage you to read
In this post, we will revisit the topic of extending the AMPS client to provide a bookmark store for stateless clients. This post is in response to requests for a simple stateless store that does not provide all of the functionality of the local stores, but instead just makes it possible for an application with very simple needs to pick up a subscription after failover. The implementation that we will discuss here is fairly limited, but should provide a starting point for less restrictive implementations. Before we begin, I would like to encourage you to read 

















 Chorded Graph
Chorded Graph Replication Matrix
Replication Matrix Force-directed Graph
Force-directed Graph